
Fiddler是一款免费且功能强大的数据包抓取软件.它通过代理的方式获取程序http通讯的数据.我们可以利用它来检测网页和服务器的交互情况.下面,我们以http://blog.cersp.com/index/1000176.jspx的网址列表的获取说明一下如何使Fiddler配合火车采集器获取网址列表,以http://bbs.locoy.com的附件下载为例说明一下cookie的获取..
Fiddler下载地址:http://www.fiddler2.com/dl/Fiddler2Setup.exe
一.网址列表的获取
现在我们打开Fiddler,按Ctrl+x,将原来的监控的内容删除,这样便于寻找记录.
我们首先打开个网页http://blog.cersp.com/index/1000176.jspx,这个页面在翻页时我们看不到地址栏里网址有变化,在打开页面查看源码时也看不到有关列表的源码.我们用fiddler监视后,找一个列表中的标题,如"简单与复杂",使用搜索功能,点菜单 Edit里的 Find Sessions.
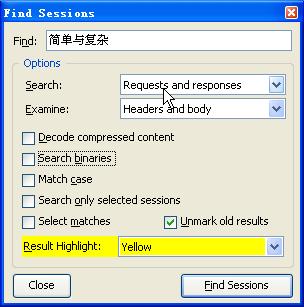
注意下边的颜色是标记找到的记录的数据,我们点击按钮Find Sessions,程序显示找到了两条有这个字符的记录,我们点击第一个数据,可以看到里边有我们需要的数据,第二条是评论.在左上角,我们可以看到是该页面是使用post方式获取到列表的.
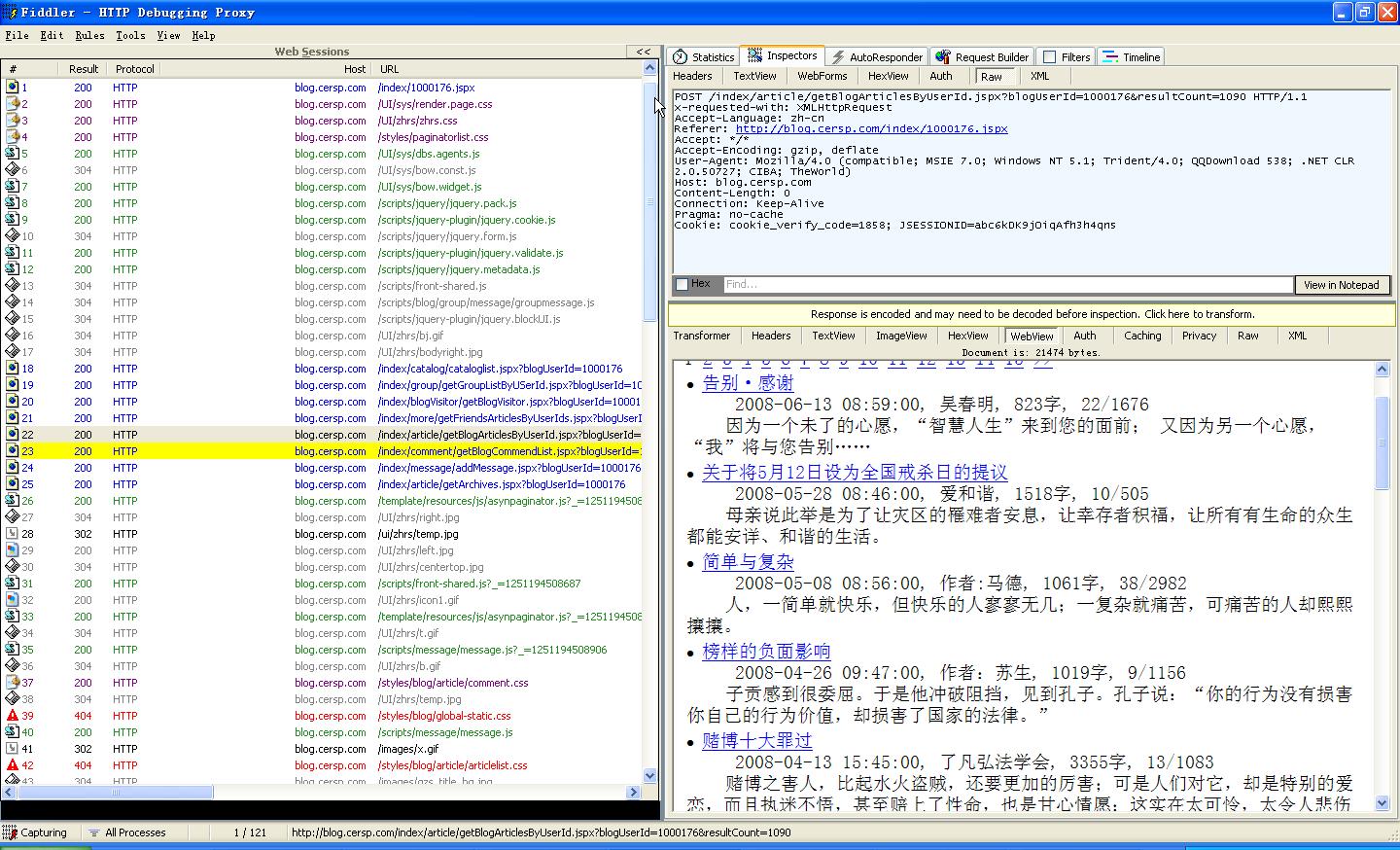
现在我们打开网页中列表的第二页,将原来的记录清空.然后对得到的结果进行对比分析.

可以看到如下结果.默认我们看到的是Header内容,我们看图中红圈,点击Raw,就可以看到发送的数据.
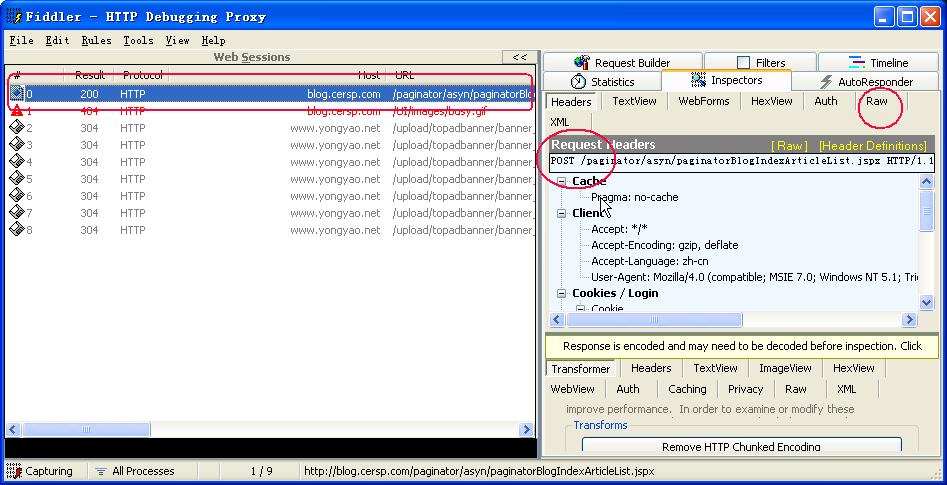 我们点击view in NotePad ,可以在记事本中打开查看发送的具体数据.
我们点击view in NotePad ,可以在记事本中打开查看发送的具体数据.
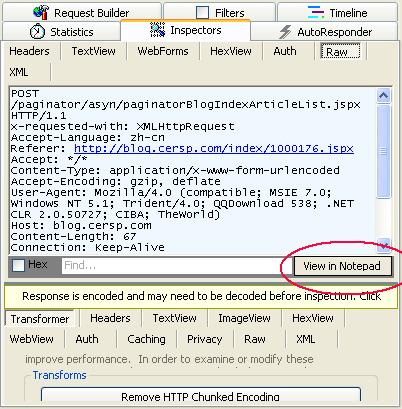
可以看到如下内容.需要注意的是,红色部分2+1就是程序里要填写的网址,也就是 http://blog.cersp.com/index/article/getBlogArticlesByUserId.jspx,蓝色部分 Pageno=2是表示第二页.
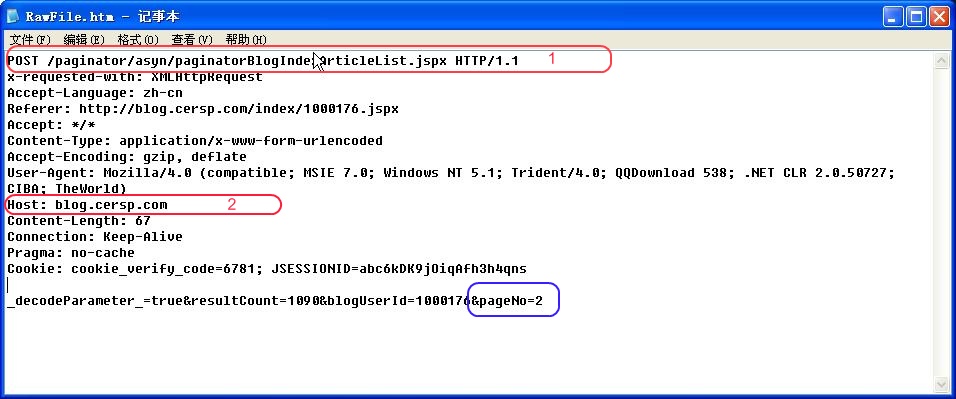
我们再访问第三页列表,可以得到如下结果 ,可以看出,改变的只是一个页数,所以我们在构造发送的数据时,只需要改变页码即可.其它的参数,一个是用户id,一个是用户文章数目,可以按需要进行修改.
现在我们看一下如果在采集器里进行设置,一个是选post方式,另一个是填写网址,最后一个是将页面部分替换成程序的[分页].并设置要采集的页数.

下边的网址选定区域也可以设置,也可以不设置,和自动获取网址是一样的.我们可以看到最后采集到了需要的网址.
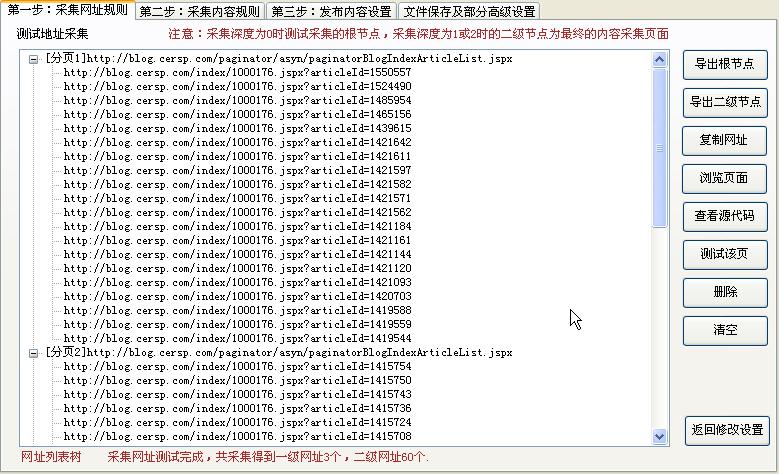
规则下载....其它相关的例子,请查看 POST方式获得网址
二,Cookie的获取
我们以http://bbs.locoy.com/spider-33617-1-1.html 的附件下载为例子,附件只有登陆以后才可以下载,未登陆前,我们采集时会看到提示登陆的内容.

我们打开fiddler,在浏览器里访问一下该页面,就可以看到Fiddler所获取的数据.
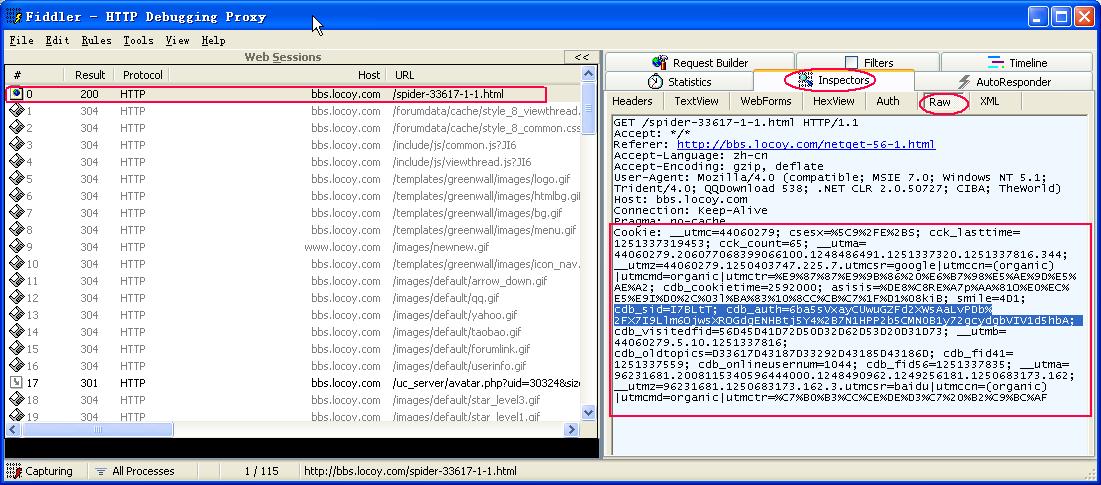
注意操作时按以上提示进行点击,方框里的内容就是cookie信息,注意开头的cookie:不用复制.对于大多数的系统来说,直接用所有的cookie就可以,dz的有些特殊,你需要只使用带_sid,_auth部分的cookie即可,也就是图中选中的部分,我们复制这部分内容,粘贴到采网址部分下部的cookie信息的地方.

然后我们再去测试,可以看到内容,并能下载到模块.
抓取cookie到些结束,相关规则 下载



相关推荐
本文档是针对fiddler的入门使用,介绍的较为详细,举得例子也比较容易懂,图文结合
抓包工具fiddler汉化版 抓包工具fiddler汉化版 抓包工具fiddler汉化版
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以让你胡乱修改的意思)。 Fiddler ...
android 抓包工具 fiddler2 一个很好用的抓包工具,下边附上教程 http://blog.csdn.net/zshq280017423/article/details/8928616
最好用,最专业的抓包工具Fiddler,软件测试人员首选测试工具
一句话 ,苹果和windowsPhone,安卓都可以进行抓取数据,最重要的是 json连接 你值得拥有,比HttpWatch 不知道强多少倍
Fiddler抓包工具,用于抓取app发起请求Fiddler抓包工具,用于抓取app发起请求Fiddler抓包工具,用于抓取app发起请求
Fiddler2 的
抓包工具Fiddler安装包,用于抓取请求地址
非常使用的抓包工具fiddler 学习测试使用开发工具 app开发调试工具 app测试调试工具。抓包工具fiddler,调试工具
一款网络抓包工具
Fiddler+Proxifier实现exe抓包功能工具包 Fiddler只能抓包浏览器请求,配合Proxifier可以同时抓包通过exe调用的请求 压缩包中同时包括了配置使用说明
史上最强的抓包工具,能够抓取包括http 、https 、ftp等协议,能够很好的分析协议包
Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具 Fiddler2抓包工具
抓包工具Fiddler2!
抓包工具,浏览网页时,同步打开抓包工具,可以实时查看网络数据请求